##《统计学习方法》学习笔记(2)逻辑斯谛回归
之前刚开始学逻辑斯谛回归,老师一直强调,这里叫“回归”,很具迷惑性,其实是分类。那为什么要叫“回归”?我们先去搞清楚一些概念
####1. 感知机与逻辑斯谛回归
有点迷惑都是用来做分类的模型,而且之后的策略又都是极大似然函数法,算法都是梯度下降等,如下图,都是要求decision boundary。那这两种方法究竟有什么区别?

拿Andrew Ng讲logistic regression上的一个例子患了tumor的分为benign和malignant之分,通过二值分类,也就是感知机的角度,我们可以直接判断这个人的肿瘤是良性还是恶性,而不同的是logistic regression给出了“ 概率 ”,病人究竟会有多大的概率会诊断为良性肿瘤。
然而学习数据却是一模一样的,x是特征,y是-1和1,没有涉及到“概率”问题,这里其实还是从上面那幅图上看,直观的,我们可以说,离 decision boundary 越远相应的取1或-1的概率越大。那么这么去表示这个概率呢?我们需要将这个值映射到一个取值为[0,1]的函数中,而
sigmoid function正好就是这样的函数,这个函数也叫logistic function:

这里使用,是为了保证为正,为什么不使用绝对值呢?因为不方便求导和求极值。这里李航的书里面把S形曲线直接译为sigmoid curve,其实是有区别的,s形曲线并非仅sigmoid函数一个。
相应的感知机的映射函数为这就是区别了吧,两种方式还是很像的。
####update
前面解释有些缺漏,两者的区别还是很大的。还有一处错误就是感知机的策略即代价函数不是最大似然函数,而是误分类点到超平面的总距离
看了一篇博文逻辑斯蒂(logistic)回归深入理解对逻辑斯谛回归进行了深入的阐述
现实生活中感知机几乎不用,而逻辑斯谛模型却还是使用的蛮多的为甚么?因为现实中的数据大多是如下图这样的 ( 这个数据集的意思就是特征x为两次exam的分数,标签y是是否录取 )
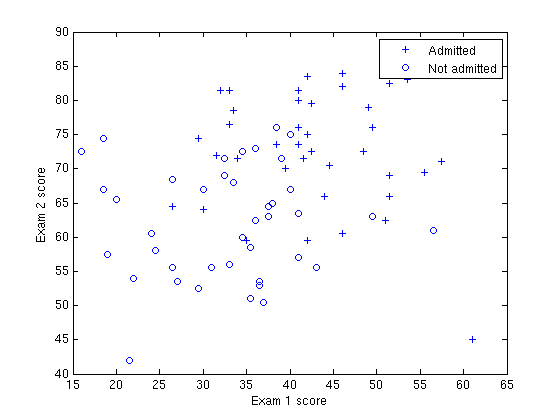
之后得到的Decision Boundary如图

咋一看分类效果太差了,但是,我们不要用这个分界面来评价logistic回归模型的好坏。我们先看下这条decision boundary 是如何得到的?然后在做讨论。
我们将X1,X2代入第3节中的  中其值大于>0.5表示允许上大学的概率大于0.5,那么剩下的区域就是不允许上大学的。那么其值=0.5的就是这个分界面。解出来之后的w•x+b=0是一个直线方程,不能因为分界面是一条直线就认为这是一个线性分类器,logistic回归没有分类的功能,logistic回归用来预测概率的,这里的分类功能是我们硬性规定的一个分类标准:把>0.5的归为一类,<0.5的归于另一类。这是一个很强的假设,因为本来我们可能预测了一个样本所属某个类别的概率是0.6,这是一个不怎么高的概率,但是我们还是把它预测为这个类别,只因为它>0.5.所以最后可能logistic回归加上这个假设以后形成的分类器的分界面对样本分类效果不是很好,这不能怪logistic回归,因为logistic回归本质不是用来分类的,而是求的概率。
中其值大于>0.5表示允许上大学的概率大于0.5,那么剩下的区域就是不允许上大学的。那么其值=0.5的就是这个分界面。解出来之后的w•x+b=0是一个直线方程,不能因为分界面是一条直线就认为这是一个线性分类器,logistic回归没有分类的功能,logistic回归用来预测概率的,这里的分类功能是我们硬性规定的一个分类标准:把>0.5的归为一类,<0.5的归于另一类。这是一个很强的假设,因为本来我们可能预测了一个样本所属某个类别的概率是0.6,这是一个不怎么高的概率,但是我们还是把它预测为这个类别,只因为它>0.5.所以最后可能logistic回归加上这个假设以后形成的分类器的分界面对样本分类效果不是很好,这不能怪logistic回归,因为logistic回归本质不是用来分类的,而是求的概率。
为什么这里貌似有些误分类点,但最后还是得到了决策边界?
因为求得的各维度线性叠加和,不是与Xi所属的类别进行比较,而是非线性映射到所属类别的概率,然后最大似然函数法求模型参数(也就是那个各维度线性叠加的权重,而后面的非线性映射logstic那里没有参数)
####2. 逻辑斯谛回归和线性回归
logistic回归,与线性回归并成为两大回归,应用范围一点不亚于线性回归,甚至有青出于蓝之势。因为logistic回归太好用了,而且太有实际意义了。解释起来直接就可以说,如果具有某个危险因素,发病风险增加2.3倍,听起来多么地让人通俗易懂。线性回归相比之下其实际意义就弱了。logistic回归与线性回归恰好相反,因变量一定要是分类变量,不可能是连续变量。分类变量既可以是二分类,也可以是多分类,多分类中既可以是有序,也可以是无序。二分类logistic回归有时候根据研究目的又分为条件logistic回归和非条件logistic回归。条件logistic回归用于配对资料的分析,非条件logistic回归用于非配对资料的分析,也就是直接随机抽样的资料。无序多分类logistic回归有时候也成为多项logit模型,有序logistic回归有时也称为累积比数logit模型。
####3. 二项逻辑斯谛回归
二项逻辑斯谛回归表示为条件概率分布为:

这里对权值向量w,输入向量x进行一下扩充,w•x+b直接写成w•x了。好常用这种方法,效果一样就是为了式子简单一点。
然后李航的书里引入了几率(odds)就是事件发生和不发生概率的比值。(Andrew的视频里没有这个阐述,有没有必要?因为后面策略也只是对于sigmoid函数来求最大似然函数的)。
设事件发生概率为p,引入logit函数也就是对数几率:
与上面Y=1情况的式子一合并就有

一开头的问题解决了,到这里回归就体现出来了,输出Y=1的对数几率是由输入x是线性函数表示的模型。即逻辑斯谛回归模型。
策略和算法部分这里就略过了。
####4. 逻辑斯谛回归R语言实现
在学习中,先直接贴上代码~
data_sample <- iris[51:150,];
m <- dim(data_sample)[1] #获取数据集记录条数
val <- sample(m, size =round(m/3), replace = FALSE, prob= rep(1/m, m)) #抽样,选取三分之二的数据作为训练集。
iris.learn <- data_sample[-val,] #选取训练集
iris.valid <- data_sample[val,] #选取验证集
#调用glm函数训练逻辑斯蒂二元模型
#glm()提供正态、指数、gamma、逆高斯、Poisson、二项分布。我们的logistic回归使用的是二项分布族binomial。Binomial族默认连接函数为logit,可设置为probit。
logit.fit <- glm(Species~Petal.Width+Petal.Length,
family = binomial(link = 'logit'),
data = iris.learn);
#生成测试数据集,实际上直接使用iris.valid
dfrm <- data.frame(Petal.Width=iris.valid$Petal.Width,
Petal.Length=iris.valid$Petal.Length);
real_sort <- iris.valid$Species; #测试数据集实际类别
prdict_res <- predict(logit.fit, type="response", newdata=dfrm); #预测数据产生概率
data.frame(predict=prdict_res, real=real_sort); #查看数据产生概率和实际分类的关系
data.frame(predict=ifelse(prdict_res>0.5, "virginica", "versicolor"), real=real_sort); #根据数据产生概率生成预测分类
table(data.frame(predict=ifelse(prdict_res>0.5, "virginica", "versicolor"), real=real_sort)); #计算分类准确度
程序包有一下提供
R语言与机器学习学习笔记